
前言
在今年夏天的时候,一个老师找到我,给我介绍了他正在做的毕业设计,他想让我帮他把算法写出来。毕业设计的课题是关于大数据的,他建议我看看这些书籍:python的、机器学习的、hadoop的。前两者我都看了,没有去看hadoop。python看的是《笨方法学习python》,机器学习看的是哪本书也记不起来了,只是看了开头的分类算法。今年三月份的时候在中国mooc上看了关于python的数据分析课程,当时是为了帮助我的一个朋友写毕业设计,当然了这个朋友是女生。其实关于这方面自己知道的仅仅是皮毛而已,无论是帮助女生写毕业设计的算法还是帮助老师写毕业设计的算法,都是在百度上查阅些资料,看一看别人的代码,后来发现百度搜索到的相关内容质量不太高,就又去了知网上看看相关的论文和期刊。
数据
老师从学校的图书馆系统中把相应借书数据搞了过来,本来说是要搞建立电子图书系统以来的所有数据,后来我听他说导出数据的过程中,服务器就宕机了,他也就作罢了。刚开始的时候给我的数据是下面这样的,我问他那个是主键,他说可能是mrac记录号、或者是读者证件号。
这些数据没有图书表也没有学生表,不过是可以去做分析的,因为数据有就可以了,只不过没有办法去验证结果,也没有办法做成能显示的的结果,原因是你根本不知道数字背后代表的意义。
后来就又给我发了这样的数据,有了读者名字和图书名字的借阅表。
有了这样的数据后,我要做三件事情,首先把所有读者整理出来,接着把所有图书信息整理出来,最后把借阅表整理出来。也就是我需要把这一张表变成三张表。上面这张表中有学生姓名和学生id,通常来说,一个学生对应一个id但也不外乎有重名的情况,但id总归是主键,是不会重复的。当我以为id是唯一的时候和以为学生姓名是唯一的时候,就得到了下面两个图片。
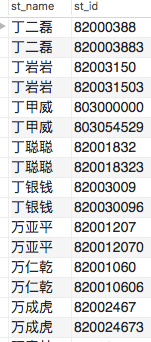
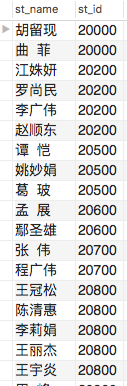
当时我看到这样的情况就有些烦恼,我想这些数据不一定准确,是需要进行下一步清洗工作的。现在我接着检索了这些数据发现了这样的情况,一个学生叫付会敏,他有两个id,但是这两个id中的其中一个id又有两个名字。也就是说付会敏对应id为820000000和820016922,这其中820000000对应两个名字付会敏和赵文杰。其实最简单的一个处理方法就是将这些脏数据全部清除掉。也就是说,将重复的学生id和重复的学生姓名,从数据库中删除,之后用相同的办法去处理图书信息。当然如果所有的数据都是这样的话,那就不能用删除这种操作才处理了,因为如果删除了,数据库里就没有了数据,没了数据那么后面的事情也都不用做了,不过这次还是蛮好的,我看了数据总量和脏数据量,比例是20比1,也就是脏数据还是少量的数据。我不记得我是如何做的了,我记得当时是分别整理出了三个excel文件,分别是学生信息和图书信息以及借阅信息。由于原文件数据过多,我在单机调试行缩减了很多数据,这样才使得单机程序跑的出结果来。
关于上面使用的查阅,在一个借阅信息表中,查询出一个name下的多个id。首先是找到那些一个名字有多个id的学生,对应下面代码的tmp表,之后在所有学生表中使用in关键字去显示这些有多个id的学生。关于sql的查询的书写规范我一直不太清楚,因为在sql中的确很少会有超过100行的查询代码。
1 | select * |
协同过滤
我在看机器学习的时候,老师叮嘱我可以先去看看协同过滤。我就在机器学习那本书中找关于协同过滤的章节,还是没有发现。后来我在百度找到一篇关于电影推荐的协同过滤算法, 跟着技术博客敲了敲代码,可是最后我去测试的时候发现推荐的八竿子都打不着。后来又大量阅读了资料,由百度到论文期刊以及一本关于推荐系统的书籍。最后在InfoQ上找到一篇讲解协同过滤的,感觉说的最为清晰明白,后来发现是翻译自Building Recommenders的。这里我就再把之前看的这篇文章再看一遍,来总结一下什么是协同过滤。首先我先来回忆一下,我记得最典型的就是向量和分类,因为在数学之美上也写过这样的文章,当时讲解了斜率和分类的关系,其原理就是托尔斯泰那句名言:幸福的家庭都是相似的,不幸的家庭各有各的不幸。我当时写的协同过滤是基于item的,这里要说一下,协同过滤一般分为基于item和基于user的,到底什么时候用哪个,要根据数据的特点来决定,当然复杂的时候也是可以混合使用的。首先是得出这本书被谁借阅过,假如有100个同学,用0来表示没有被借过,用1来表示被借过。那么这就是一个有100项的向量。