
英文描述
Counting Leaves (30)
A family hierarchy is usually presented by a pedigree tree. Your job is to count those family members who have no child.
Input Specification:
Each input file contains one test case. Each case starts with a line containing 0 < N < 100, the number of nodes in a tree, and M (< N), the number of non-leaf nodes. Then M lines follow, each in the format:ID K ID[1] ID[2] … ID[K]
where ID is a two-digit number representing a given non-leaf node, K is the number of its children, followed by a sequence of two-digit ID’s of its children. For the sake of simplicity, let us fix the root ID to be 01.
Output Specification:
For each test case, you are supposed to count those family members who have no child for every seniority level starting from the root. The numbers must be printed in a line, separated by a space, and there must be no extra space at the end of each line.
The sample case represents a tree with only 2 nodes, where 01 is the root and 02 is its only child. Hence on the root 01 level, there is 0 leaf node; and on the next level, there is 1 leaf node. Then we should output “0 1” in a line.
Sample Input:
2 1
01 1 02
Sample Output:
0 1
中文描述
统计叶子
一个家庭等级体系通常被一个描述为一个家谱树被提出。你的工作是统计那些没有孩子的家庭成员。
输入规格:
每个输入文件包含一个测试用例。每个用例开始的一行包含N和M,N(0 < N <100)代表一棵树节点的个数,m(m 0="" 1="" 2="" <="" n)代表这棵的非叶子节点。接下来的m行,每一行的格式为:id="" k="" id[1]="" id[2]="" ...="" id[k]。id是一个由2个数字组成的一个数,它被用来描述非叶子节点,k是它所包含孩子节点的个数,接着是一个由他们的孩子的2个数字组成的一个序列。为了简单期间,让我们来设置root的id为01。="" **输出规格:**="" 每一个测试用例,你应该统计出,那些家庭成员中,从root开始的每一层开始没有孩子的成员。这个数字必须被打印在一行内,被空格分隔,并且在这一行末尾没有额外的空格。这个示例描述了一个只有2个节点的树,01是root且02是唯一的孩子。因此在root-01的层,没有一个叶子节点;并且在下一层,有1个叶子节点。那么我们应该在一行内输出。="" **样例输入:**="" 01="" 02="" **样例输出:**="" 1<="" font="">
分析与解题
问题:统计一棵树中,每层中叶子节点的个数。今天想多说一点,刚读到这个题的时候连树都没想到,就是硬想,没有解决方法。随后去看了ZJU提供的参考代码说用BFS或者DFS都可。看了个title后我就在想,的确是,题中虽然说了是树但为说是二叉树,显然图是包含树的,也就是说所有适用于图的算法在树或者二叉树中都是试用的,不同的地方可能是不同的解决方案代码效率是不同的。之后我去参看了《算法导论》中关于BFS和DFS的内容,因为之前在写最短路径时有一种是利用拓扑排序来写的,但是拓扑排序中又用到了DFS,因此我先看的是DFS算法。《算法导论》中的DFS写的相对复杂,因为书本原本的意思希望你能尽可能多的去理解关于此算法的相关性质,说起性质其实就是让你更理解它。比如算法中设置了很多属性,比如仅仅是标记它就设置了三种:白色、灰色和黑色,分别代表未访问节点、发现节点和访问结束节点。又在访问过程中设置了访问时间,开始时间和结束时间。通过这些属性的设置让你更清楚地看见算法的执行过程。刚开始我是想要参看DFS去写出此算法,我看到《算法导论》中描述的括号化性质和此题中的层问题很相似,图就类似于下面的,你看看后可能更容易理解我在说什么。这个性质在算法上的体现就是开始时间和结束时间的体现,当然你可以给他改成相应的括号。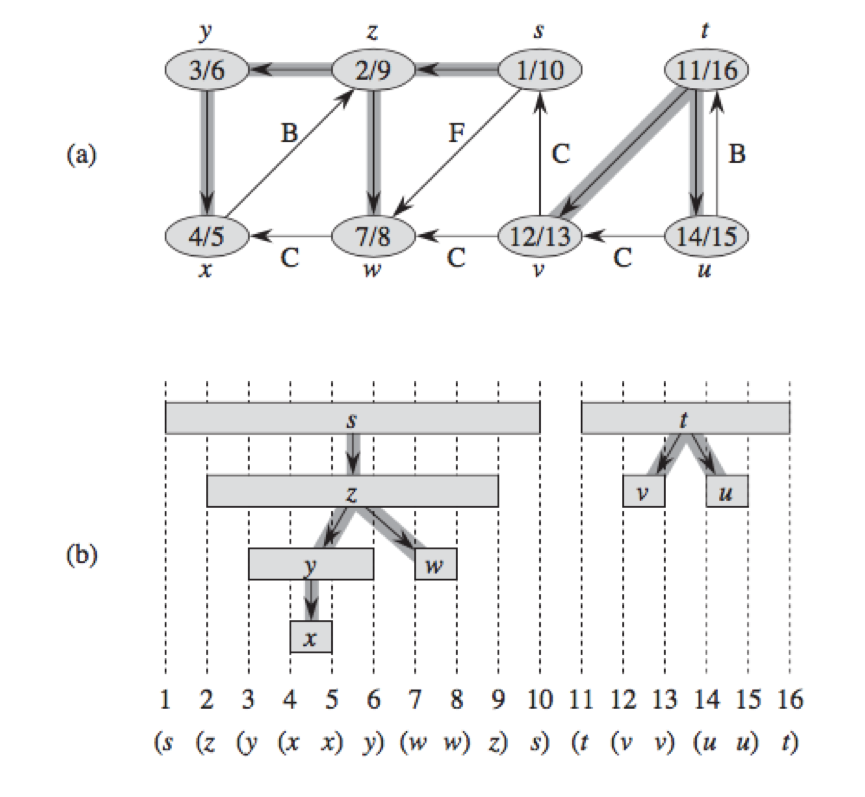
图b中的两颗树,通过开始时间和结束时间来标记括号化性质,我发现括号化刚好可以描述层数。但是当我在尝试去更改代码的时候发现确不知道通过什么手段来确认这个括号,思来想去也没有什么办法。
次日,我想着把《算法导论》关于图算法的基础这一张看一遍,就从最基础的章节开始读起,当我读到BFS的时候,发现,BFS其实就是按照图的层次来进行遍历的,后来又看到算法中带的d(distance)属性,描述的不就是我想到的层数吗,也就是此题中的层数。我就把BFS的代码该了一番,通过了这个程序。我想这个程序用DFS也能写出来,其实遍历不变,依旧去统计d值就可以了。
关于数据结构。我在看ZJU的代码的时候他说没有去构建树。我就想如果再去构建树或者图的话也会相对麻烦,这让我想起之前和Femy聊得时候,Femy也说PAT的输入是相当麻烦的。所以我就顺着原题的输出是写BFS算法了。在考虑输入的时候,我本来是决定去写结构体什么的,后来发现直接给一个二维数组是相当省事(关于省事,我也是看了ZJU的代码,比如在emergency那个题中,我写了快2百行,用的是邻接表去实现图,后来看了它直接给了一个邻接矩阵,感觉又省事又简单,所以我后来也决定,写给编译器的代码,不用易读),关于此算法的输入就使用了了一个二维数组。每行的前两个数字代表题中ID和K之后的就代表ID的孩子们。关于数据的存储我一会去详细看一下ZJU的代码,应该能学到更好的方法。
C语言实现
1 | /* counting leaves |